Description: BicBucStriim is a data pipeline and integration platform that allows you to easily combine data from multiple sources, transform and enrich data on the fly, and route it to various targets. It provides a code-free environment to build scalable data pipelines without infrastructure.
Type: Open Source Test Automation Framework
Founded: 2011
Primary Use: Mobile app testing automation
Supported Platforms: iOS, Android, Windows
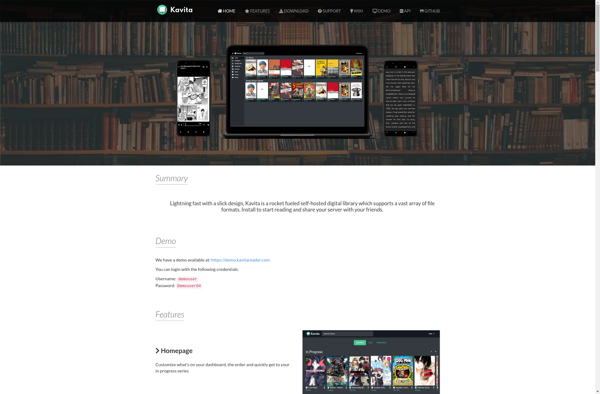
Description: Kavita is an open-source web application for managing digital comic book libraries and reading comics. It allows users to easily browse, organize, and read their digital comics from any device with a web browser.
Type: Cloud-based Test Automation Platform
Founded: 2015
Primary Use: Web, mobile, and API testing
Supported Platforms: Web, iOS, Android, API