Description: DeepSound is an AI-powered audio editing software that allows users to isolate, extract, and manipulate individual sounds and components within complex audio recordings. It utilizes deep learning for advanced audio analysis and processing.
Type: Open Source Test Automation Framework
Founded: 2011
Primary Use: Mobile app testing automation
Supported Platforms: iOS, Android, Windows
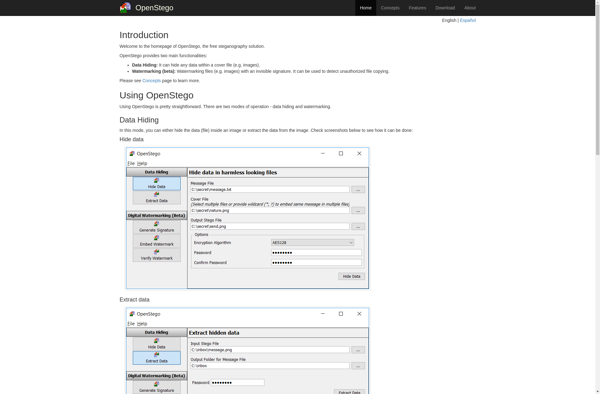
Description: Openstego is an open source steganography application that allows users to hide data within image and audio files. It provides features like password protection, compression, and encryption to safely conceal messages.
Type: Cloud-based Test Automation Platform
Founded: 2015
Primary Use: Web, mobile, and API testing
Supported Platforms: Web, iOS, Android, API