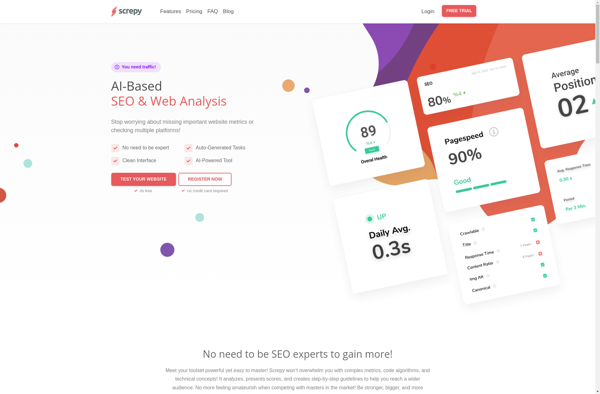
Screpy
Description: Screpy is an open-source web scraping framework for Python. It provides a simple API for extracting data from websites, handling JavaScript pages, caching responses, and more. Ideal for basic web scraping tasks.
Type: software
Pricing: Open Source
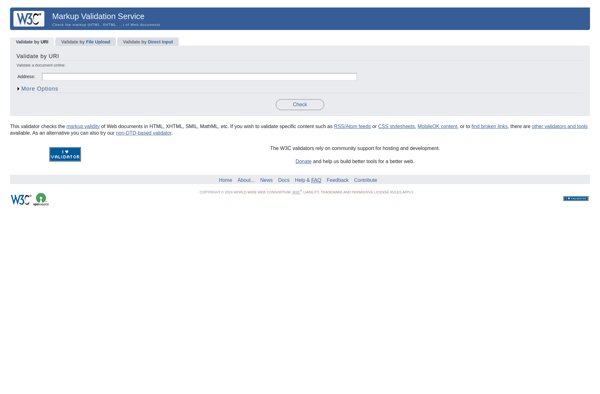
W3C Markup Validation Service
Description: The W3C Markup Validation Service is a free tool that checks HTML and XHTML documents for conformance to W3C standards. It can help identify potential issues in web pages and ensure they use valid markup.
Type: software