Description: Castle Vox is an open-source voice cloning software that allows users to create synthesized voices from audio samples. It uses deep learning techniques to analyze and recreate the tonal qualities and speech patterns from just a few minutes of audio.
Type: Open Source Test Automation Framework
Founded: 2011
Primary Use: Mobile app testing automation
Supported Platforms: iOS, Android, Windows
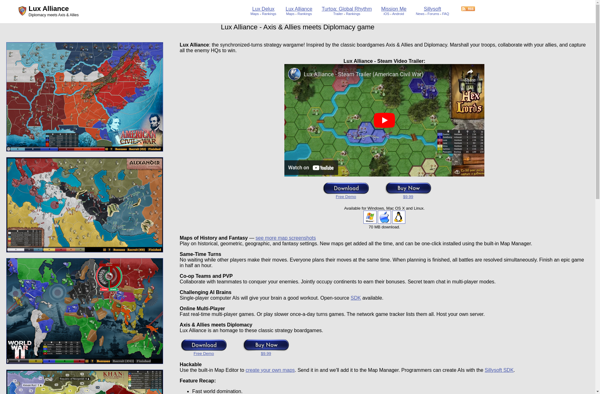
Description: World Conqueror 1945 is a World War II strategy game where players take control of the Axis or Allied powers during WWII and attempt to conquer the world through military force. The game features historical commanders, units, and territories in a turn-based battle format on a global scale.
Type: Cloud-based Test Automation Platform
Founded: 2015
Primary Use: Web, mobile, and API testing
Supported Platforms: Web, iOS, Android, API