Faker
Description: Faker is an open source Python library that generates fake data for testing purposes. It can generate random names, addresses, phone numbers, texts, and other fake data to populate databases and applications during development.
Type: software
Pricing: Open Source
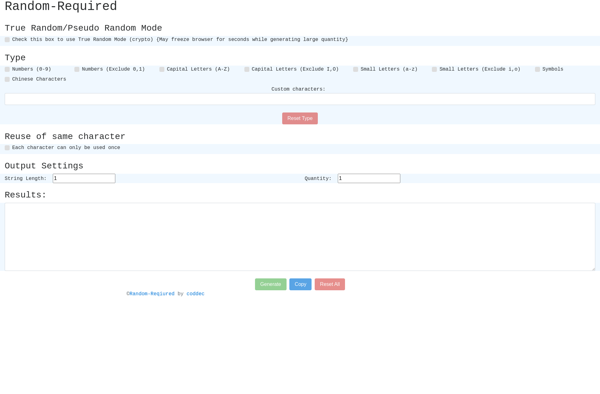
Random-Required
Description: Random-Required is a software that helps generate random data for testing and development purposes. It allows users to easily create randomized datasets including names, addresses, numbers, strings, etc. Useful for populating mock databases, stress testing systems, and more.
Type: software