ArchiveBox
Description: ArchiveBox is an open source self-hosted web archiving solution that lets you archive web pages and collect media assets. It aims to create local, browsable copies of sites from the internet.
Type: software
Pricing: Open Source
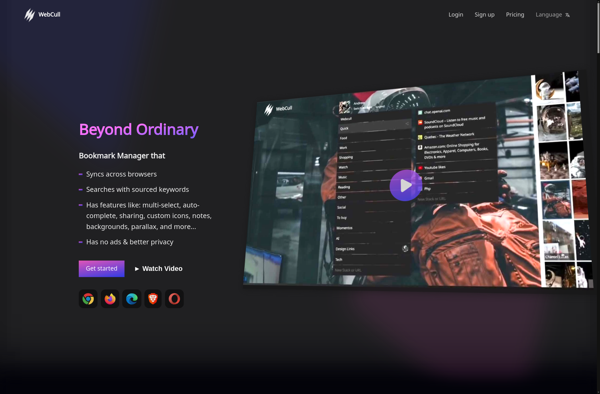
WebCull
Description: WebCull is a web scraping and data extraction software. It allows users to easily extract data from websites without coding through an intuitive point-and-click interface. WebCull can scrape data, images, documents, and media from web pages.
Type: software