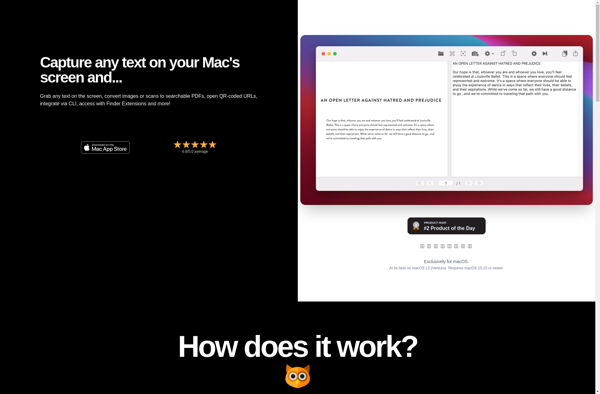
OwlOCR
Description: OwlOCR is an open-source optical character recognition software. It can extract text from images and PDF files and convert it into editable document formats. Useful for digitizing paper documents and making their content searchable.
Type: software
Pricing: Open Source
Tesseract
Description: Tesseract is an open source optical character recognition (OCR) engine. It can recognize text in images and convert it into editable text. It supports over 100 languages and can handle distorted or low-quality images.
Type: software
Pricing: Open Source