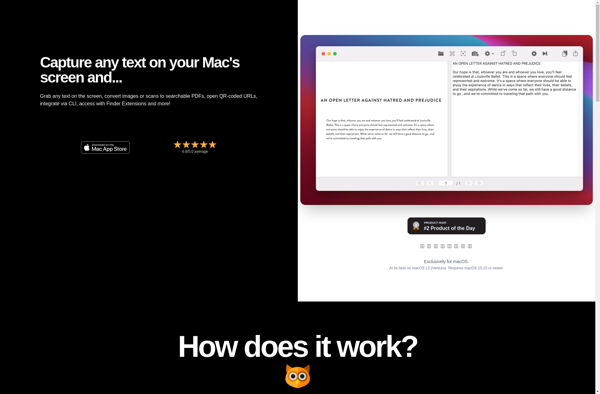
OwlOCR is an open-source optical character recognition software. It can extract text from images and PDF files and convert it into editable document formats. Useful for digitizing paper documents and making their content searchable.
Extract text from images and PDF files with OwlOCR, an open-source optical character recognition software, digitize paper documents and make their content searchable.
What is OwlOCR?
OwlOCR is an open-source, offline optical character recognition (OCR) software for Windows, Mac and Linux. It allows extracting text from images such as scanned documents, screenshots, and photos, as well as PDF files.
Some key features of OwlOCR include:
Supports over 40 languages for OCR
Outputs extracted text into Word, Excel, PDF, HTML, text and other formats
Provides high accuracy for clean scans and photos
Allows editing OCR results before exporting text
Handles documents with both text and images
Completely free and open-source
OwlOCR enables digitizing paper documents by converting them into editable formats. The recognized text can then be edited, searched, archived and shared easily. This makes it a great scanning software for both personal and business use.
As it runs offline without requiring internet connection, OwlOCR ensures privacy and data security. The open-source nature also guarantees full transparency on how it handles user data.
OwlOCR Features
Features
Extracts text from images
Extracts text from PDF files
Converts extracted text into editable formats like Word, Excel, plain text etc
Supports over 40 languages for OCR
Can handle scanned documents, screenshots, photos etc
Open source software
Available on Windows, Linux and Mac
Pricing
Open Source
Pros
Free and open source
Accurate OCR with support for many languages
Extracts text from various file formats
Converts into editable document formats
Available on multiple platforms
Cons
Lacks some advanced features like table recognition
Adobe Acrobat DC is a suite of applications and services developed by Adobe Systems for working with PDF files, which is a widely used file format for document exchange. Acrobat DC stands for Document Cloud, reflecting Adobe's focus on cloud-based services and collaborative workflows. Key Components and Features: Adobe Acrobat...
CamScanner is a popular mobile application available for both iOS and Android devices. It allows users to scan paper documents and photos into digital copies using their phone's camera.Once scanned, CamScanner utilizes advanced image processing technology to automatically crop, enhance, and sharpen scanned documents to improve clarity and readability. Some...
NAPS2 (Not Another PDF Scanner 2) is a free, open source document scanning and PDF creation software for Windows. It provides an easy to use interface to control document feeder scanners and convert scans into searchable PDF, TIFF, JPG, PNG, and other image file formats.Key features of NAPS2 include:Scan to...
ABBYY FineReader PDF is an optical character recognition and PDF software application developed by ABBYY. It is designed to help users scan paper documents and images, including photos, screenshots, PDF files, and more, and convert them into editable and searchable digital formats.Some of the key features of ABBYY FineReader PDF...
TextSniper is an AI-powered text extraction software that helps users save time by extracting the text from images and documents. Its powerful OCR engine accurately recognizes text in over 100 different file formats including images, scans, PDFs, Microsoft Office documents, presentations, ebooks, web pages, and more.Some of the key features...
CopyFish is an open-source plagiarism detection software designed for teachers and professors to check student submissions for copied or unoriginal content. It works by comparing student papers, essays, code, and other work against various databases and search engines to identify matched text.Some key features of CopyFish include:Open-source web application that...
Prizmo is a powerful scanning and optical character recognition (OCR) application for iOS and macOS. It allows you to quickly scan documents, receipts, business cards, photos, whiteboards and more using your device's camera. The state-of-the-art OCR engine can recognize text in over 60 languages.Once scanned, Prizmo can export your files...
Paperwork is an open source document manager software designed for easy organization and search of documents on your computer.Key features of Paperwork include:Open source software licensed under GPLv3Available on Linux, Windows, and MacStore documents locally on your computer, supports PDF and imagesFolder-based hierarchy for organizing documentsTag documents for more flexible...
Chronoscan is a comprehensive time tracking and productivity platform designed for freelancers, agencies, consultants, accountants, lawyers, and remote teams. It allows users to accurately track time spent on projects and tasks, generate detailed reports and invoices, log billable hours, record expenses, set budgets, automate billing, and gain valuable insights into...
Image To Text is an optical character recognition (OCR) software designed to convert images containing text into digital text documents. It works by analyzing image files such as scanned paper documents, PDF files, screenshots, smartphone images, and more, to identify text characters and convert them into fully editable text.Some key...
OSS Document Scanner is an open-source document scanning application for Linux operating systems. It provides an easy way to scan paper documents and save digital copies on your computer.Some key features of OSS Document Scanner include:Scanning documents and saving them as PDFs or common image formats like JPG and PNGAutomatically...
GImageReader is a free, open source optical character recognition (OCR) software for Linux operating systems. It provides users with the ability to scan paper documents, images, screenshots, and even PDF files, and convert the text in them to searchable and editable digital text files.Some of the key features of GImageReader...
Adobe Scan is a mobile scanning app developed by Adobe Inc. It is available on both iOS and Android platforms.The app allows users to capture paper documents, receipts, forms, business cards, whiteboard notes and more using the camera on their mobile device. It can automatically detect the document in the...
Tesseract is an optical character recognition (OCR) engine that was originally developed by Hewlett-Packard in the 1980s and open sourced in 2005. It is now maintained by Google.Tesseract allows for the recognition of printed text in images, such as scanned documents and photos. It can handle a variety of image...
The Google Cloud Vision API is a powerful set of APIs that provide pre-trained machine learning models through a REST API to extract useful information from images. It is part of Google Cloud's machine learning offerings.Some of the key capabilities of Cloud Vision API include:Label Detection - automatically label images...
OpenScan is an open source document scanning application designed for Linux operating systems. It provides users with an easy way to scan paper documents, photos, and other physical media directly into digital file formats.Some key features of OpenScan include:Scans directly into common file types like PDF, JPEG, PNG, and TIFFSupports...
FreeKapture is a free and open-source screenshot capture utility for Windows. It provides a simple but capable set of tools for taking screenshots and basic image annotations.With FreeKapture, you can take fullscreen, active window, rectangular region, and scrolling webpage screenshots. It has configurable hotkeys for triggering different capture modes quickly....
LensOCR is an innovative optical character recognition (OCR) software that utilizes advanced AI and machine learning technology to accurately extract text from images. It has a user-friendly mobile app interface that allows users to simply take photos of documents, receipts, notes, business cards, whiteboards, and other text-heavy images, which it...
OCRopus is an open source optical character recognition (OCR) engine optimized for scanned documents. Developed by researchers at the University of New York at Buffalo, it incorporates algorithms tailored towards analyzing document images rather than natural scenes.Some key capabilities of OCRopus include:Handling challenging fonts, layouts, and image quality issues common...
Adlib PDF is a powerful PDF editing and management software designed to provide users with advanced capabilities for working with PDF documents. It goes far beyond just viewing and printing PDFs by enabling users to edit, annotate, redact, secure, optimize and even create PDF files.Key features of Adlib PDF include...
Anyline is an optical character recognition (OCR) and scanning software that allows users to instantly capture and extract data from documents, IDs, meters, packages, and more using the camera on a mobile device such as a smartphone or tablet. It works completely offline without an internet connection and has industry-leading...
CloudScan is a comprehensive cloud security and compliance monitoring platform designed to provide visibility and control across public cloud environments like AWS, Azure, and GCP. It helps identify misconfigurations, data leaks, suspicious user activity, and threats to workloads in the cloud.Key features of CloudScan include:Continuous scanning of cloud assets like...
PDF OCR (Optical Character Recognition) software enables you to convert scanned PDF documents and image-PDFs into searchable and editable PDF files. It analyses image documents using OCR technology to identify text characters and convert images into actual text.The key benefit of PDF OCR software is that itunlocks scanned PDFs and...
Text UP is a text editor and word processor software designed to provide a simple, no-frills writing experience. Unlike feature-packed office suites, Text UP focuses only on core writing and basic formatting tools, making it an appealing option for users who want a lightweight program for creating documents, notes, and...
OCRmyPDF is an open source command-line program and Python library that applies optical character recognition (OCR) to PDF documents. It takes an existing PDF as input and generates a new searchable PDF as output with an invisible text layer over images.OCRmyPDF is designed to work on entire directories of PDFs...
Smart Scanner is an advanced document scanning and management software designed to simplify and automate the process of digitizing paper documents. One of its standout features is its intelligent cropping algorithm that can automatically detect the edges of documents in a scan and crop them to extract individual pages.This is...
OmniPage Cloud Service is an optical character recognition (OCR) and document conversion solution delivered through the cloud. It provides users with the ability to scan paper documents and convert them to popular digital formats like PDF, Word, Excel, and more using advanced OCR technology.Some key features of OmniPage Cloud Service...
Condense is an open-source desktop application used to combine multiple PDF documents into a single file. It provides an easy way to organize and merge PDFs without the need for expensive software.Some key features of Condense include:Intuitive drag-and-drop interface for combining PDFsSupport for adding, deleting, rotating, and sorting pagesTabs for...
Ocrkit is an open-source optical character recognition (OCR) engine for Linux operating systems. It allows you to convert scanned documents and images containing text into editable and searchable digital documents.Some key features of Ocrkit include:Extracts text from image files like JPG, PNG, TIFF and PDF documentsSupports over 100 languages including...
OCR Online is a free web-based optical character recognition (OCR) service that allows you to convert scanned documents, PDF files, and images containing text into editable and searchable text files. It is very easy to use - you simply upload your file, select the language if it contains non-English text,...
Text-R is a comprehensive text analysis platform designed for researchers, marketers, product managers, and other professionals who need to make sense of qualitative text data. The software provides a wide range of text analysis capabilities including:Sentiment analysis - Determine if text conveys positive, negative or neutral sentimentEntity and concept extraction...
TextDetective is a free plagiarism detection software used to check for copied or spun content. It allows users to copy and paste text or upload documents to scan against its extensive database of webpages and published works to identify duplicated content.Key features of TextDetective include:Checks text against billions of online...
contentCrawler is a feature-rich web scraping and data extraction tool used by data scientists, analysts, and developers to collect online data. It provides an intuitive graphical interface to scrape data from websites without needing to write any code.Some of the key capabilities of contentCrawler include:Visual point-and-click scraping - Easily extract...
Free OCR to Word is free optical character recognition software designed for individual users to convert scanned paper documents, PDF files, and images into editable Microsoft Word documents. It uses OCR technology to detect text in image files and convert it into digital text you can edit on your computer.Some...
ZoomReader is assistive technology software designed to make reading and seeing easier for people with visual impairments or reading disabilities such as dyslexia. Its key features include:Text-to-speech with natural sounding voices to read websites, documents, ebooks aloudMagnification up to 36x for enlarging text and imagesColor contrast adjustment to make text...
doXiview is a feature-rich, open source PDF viewer and editor that allows you to view, annotate, sign, and edit PDF documents. Developed by xenonsoftware, doXiview is free to download and use, even for commercial purposes.Some of the key features of doXiview include:Intuitive PDF viewer with smooth scrolling and fast load...
OCR Pro+ is an advanced optical character recognition and document scanning application. It has powerful OCR capabilities that allow you to scan paper documents such as PDFs, images, or printed text, and convert them into fully editable digital formats such as Word, Excel, searchable PDFs, and more.Some key features of...