CVAT is an open source computer vision annotation tool for labeling images and video. It allows for collaborative annotation of datasets with features like predefined tags, interpolation of bounding boxes across frames, and review/acceptance workflows.
Open source tool for collaborative image & video annotation, featuring predefined tags, bounding box interpolation, and review workflows
What is Computer Vision Annotation Tool (CVAT)?
CVAT is an open source web-based tool for computer vision annotation and labeling of images, video, and other data. It allows users to draw bounding boxes, segment objects, track objects across frames, assign tags, and more. Some key features of CVAT include:
Platform agnostic - works in any modern browser
Annotation tracking - interpolate bounding boxes across multiple frames
Predefined tags - quickly assign common tags to annotations
Review system - create review/acceptance workflows for annotation quality control
Collaborative - multiple users can work on the same projects
Plugin ecosystem - supports writing plugins to extend functionality
CVAT is implemented using modern web development stacks including Django, React, and Canvas. It can be self-hosted on an internal server or hosted in the cloud. The goal of CVAT is to provide a flexible and extensible computer vision annotation platform for teams to collaborate on dataset labeling and model training.
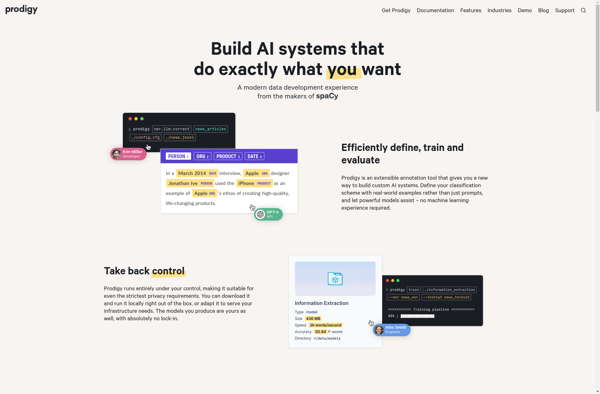
Prodigy ML is an efficient open-source data annotation tool for building machine learning models. It accelerates machine learning model development by making the data annotation process faster and more collaborative across teams.Key features of Prodigy ML include:Active learning suggestions to prioritize annotations for maximal model improvementPre-annotation with existing models to...
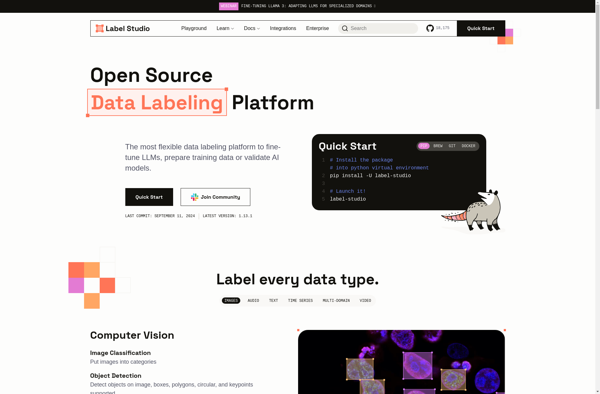
Label Studio is an open source data labeling platform for machine learning applications. It allows users to annotate text, image, audio, video and time series data to generate labeled datasets for training machine learning models.Some key features and capabilities of Label Studio include:Supports diverse data types - text, images, audio,...
Amazon SageMaker Data Labeling is a service that provides access to human labelers so that you can easily and quickly label large datasets for machine learning. Some key features include:Get access to a workforce of pre-qualified human labelers who can label images, videos, text, and more for your machine learning...
Supervisely is a no-code platform designed to make computer vision and machine learning more accessible. It provides a complete set of tools for annotating data, training neural networks, and deploying models without the need for coding.Some key features of Supervisely include:Intuitive web-based interface for image, video, and 3D data annotation.Pre-trained...
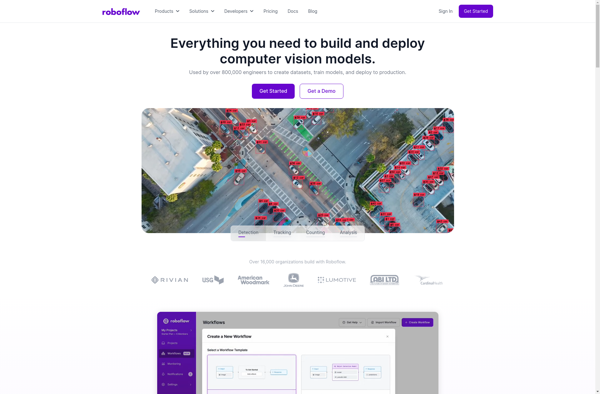
Roboflow is a no-code computer vision platform designed to help machine learning engineers streamline the dataset preparation process for training deep learning models. It provides a suite of tools for annotation, data management, augmentation, and export, eliminating the need to write tedious data preprocessing code.Some key features of Roboflow include:Image...
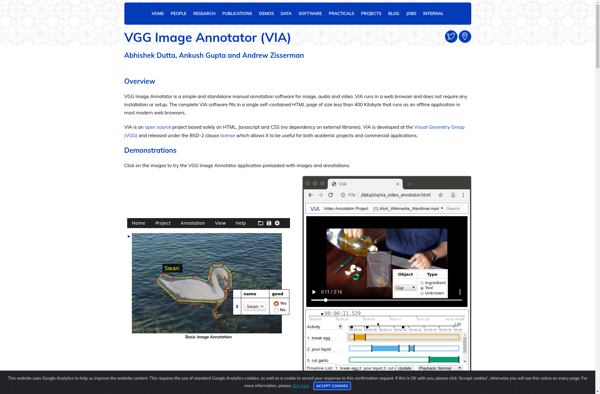
VGG Image Annotator (VIA) is an open source web-based image annotation tool for easily labeling images to generate datasets for machine learning and computer vision research. It allows users to mark up images with shapes like bounding boxes, circles, polygons to identify objects or regions of interest.Some key features of...
UniversalDataTool is a powerful, free and open-source data analysis and visualization software for Windows, Mac and Linux. It can connect to a wide variety of data sources including CSV, Excel, SQL databases, REST APIs and more to import data for analysis.Some of the key features of UniversalDataTool include:Interactive and customizable...
Label Box is a cloud-based data labeling platform designed to help teams prepare and manage data to train machine learning and artificial intelligence models. It provides a suite of collaborative tools for labeling all types of data including images, text, audio and video.Key features of Label Box include:Image, text, audio...
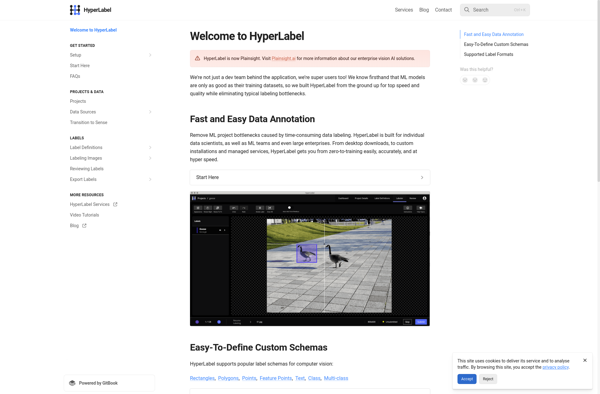
HyperLabel is label, barcode, and tag design software used to create custom product and inventory labels. This desktop program has an intuitive drag-and-drop interface that allows users to easily design multiple professional labels, tags, and barcodes without the need for graphic design experience.With HyperLabel, you can choose from over 5000...
Edgecase.ai is an end-to-end AI-powered test automation platform for modern software teams. It helps automate all stages of testing including test design, test execution, and test analysis.Key capabilities and benefits include:AI-based test case generation - Edgecase automatically generates test cases using advanced AI/ML algorithms to provide comprehensive test coverage.Automated test...
Dataloop AI is an end-to-end data management and operations platform designed to help companies prepare high-quality datasets for machine learning. It provides a comprehensive set of tools to automate repetitive data tasks and allows non-technical users to easily annotate, manage and track datasets.Key features of Dataloop AI include:Intuitive graphical interface...
OnePanel is an open-source platform that simplifies deploying and managing applications and infrastructure on Kubernetes. It provides a graphical user interface and automation tools to streamline Kubernetes workflows.Some key features of OnePanel include:App Store - Browse and deploy preconfigured applications like WordPress, JupyterHub, Airflow and more with just a few...