contentCrawler
Description: contentCrawler is a powerful web scraping and data extraction tool. It allows you to crawl websites, extract data, and save it structured formats like CSV or JSON. Some key features include visual point-and-click scraping, JavaScript rendering, proxies and automation.
Type: software
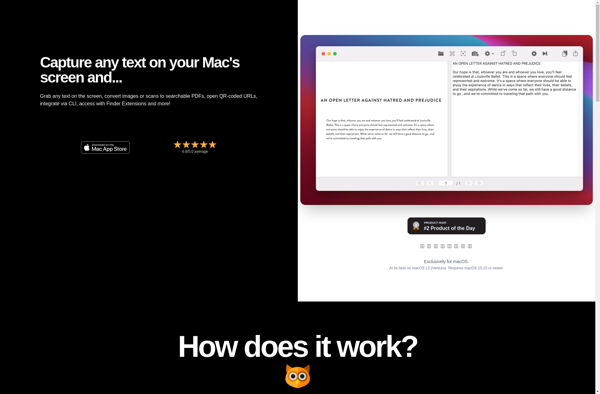
OwlOCR
Description: OwlOCR is an open-source optical character recognition software. It can extract text from images and PDF files and convert it into editable document formats. Useful for digitizing paper documents and making their content searchable.
Type: software
Pricing: Open Source