Amazon Kinesis is a managed service that allows for real-time streaming data ingestion and processing. It can ingest data streams from multiple sources, process the data, and route the results to various endpoints.
Amazon Kinesis: Real-Time Data Ingestion & Processing Service
A managed service allowing real-time streaming data ingestion, processing, and routing to multiple endpoints from diverse sources.
What is Amazon Kinesis?
Amazon Kinesis is a cloud-based managed service offered by Amazon Web Services (AWS) to allow for real-time streaming data ingestion and processing. It is designed to easily ingest and process high volumes of streaming data from multiple sources simultaneously, making it well-suited for real-time analytics and big data workloads.
Some key capabilities and benefits of Amazon Kinesis include:
Scalable data streams that can ingest gigabytes of data per second from hundreds of thousands of sources
Real-time processing of streaming data as soon as it arrives to enable near-instant analytics and insights
Customizable data processing through Kinesis Data Analytics and other AWS analytics services
Easy integration with a variety of data sources like web/mobile apps, IoT devices, and more through Kinesis agents and producers
Durable storage of streaming data for later replay and reprocessing needs
High availability and durability built in to handle data streams 24/7
Amazon Kinesis integrates closely with other AWS services like S3, Redshift, and Lambda to provide a complete platform for streaming data intake, processing, analysis, and storage. The service handles the underlying infrastructure to simplify real-time analytics at any scale.
Amazon Kinesis Features
Features
Real-time data streaming
Scalable data ingestion
Data processing through Kinesis Data Analytics
Integration with other AWS services
Serverless management
Data replay capability
Pricing
Pay-As-You-Go
Pros
Handles massive streams of data in real-time
Fully managed service, no servers to provision
Automatic scaling to match data flow
Integrates nicely with other AWS services
Replay capability enables reprocessing of data
Cons
Can get expensive with high data volumes
Complex to set up and manage
Limits on maximum stream size and shard throughput
Talend is an open source data integration and management platform designed to help organizations effectively collect, transform, cleanse and share data across systems and teams. Some key capabilities and benefits of Talend include:Graphical drag-and-drop interface to build data integration jobs and workflows without codingOver 900 pre-built data connectors to leading...
Databricks is a cloud-based platform for running Apache Spark workloads. It was founded by the creators of Apache Spark and provides a managed Spark environment to analyze massive datasets. Key features of Databricks include:Fully managed Spark clusters - Databricks handles all the infrastructure and configuration so you can focus just...
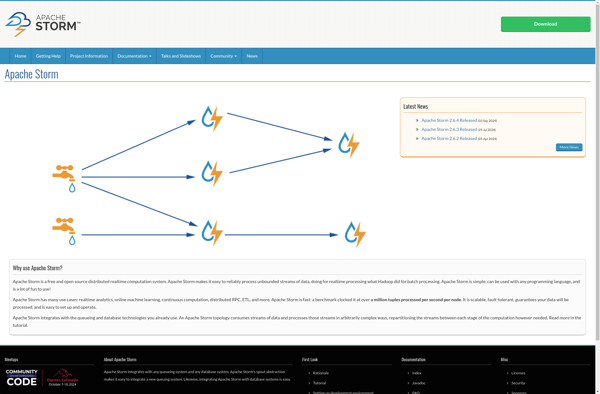
Apache Storm is an open source distributed realtime computation system for processing large volumes of high-velocity data. It provides capabilities for realtime data processing, data integration, extracting valuable insights from data streams, online machine learning, and more.Storm is designed to be fast, scalable, and robust. It can process over a...
StreamSets is an open-source data integration platform optimized for big data. It provides a simple, low-code way to build and manage continuous data pipelines to move large volumes of data between a variety of sources and destinations.Some key capabilities and benefits of StreamSets include:Drag-and-drop graphical interface to build pipelines visually...
Apache Hadoop is an open source software framework for distributed storage and distributed processing of very large data sets on computer clusters. Hadoop was created by the Apache Software Foundation and is written in Java.Some key capabilities and features of Hadoop include:Massive scale - Hadoop enables distributed processing of massive...
Apache Spark is an open-source distributed general-purpose cluster-computing framework designed for large-scale data processing and analytics. Some key points about Apache Spark:It provides a fast and general engine for large-scale data processing that runs workloads 100x faster than Hadoop MapReduce in memory, or 10x faster on disk.It supports Java, Scala,...
Disco is an open-source MapReduce framework originally developed by Nokia for distributing the computing workloads of extremely large data sets across clusters of commodity hardware. It is designed to be scalable, fault-tolerant and easy to use.Some key features of Disco MapReduce include:Automatic parallelization and distribution of MapReduce jobsFault tolerance -...
Apache Beam is an open source, unified programming model that defines pipelines for batch and streaming data processing. Beam provides a simple, Java/Python SDK for building pipelines that can run on multiple execution engines.Key aspects of Apache Beam include:Portability - Beam abstractions allow pipelines to be executed across different runners...