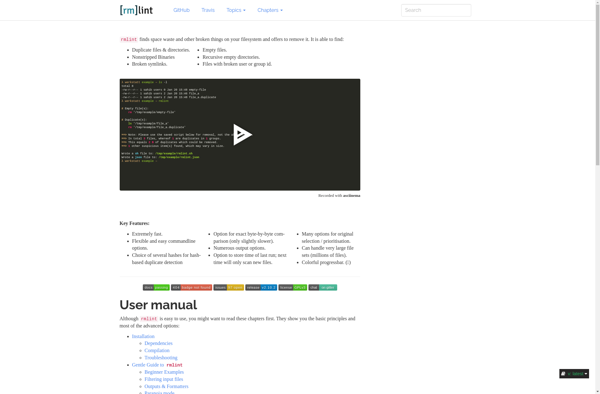
rmlint is a tool that finds duplicate files on your filesystem. It can identify identical and similar files that waste disk space. rmlint scans directories recursively and builds a database of file checksums, allowing it to quickly find duplicates.
rmlint finds duplicate files on your filesystem, identifying identical and similar files that waste disk space. Scans directories recursively and builds a database of file checksums for quick duplicate detection.
What is Rmlint?
rmlint is an open source command line tool that searches for duplicate files on Linux and Unix-like systems. It scans the filesystem, building up a database of file checksums, sizes, and other metadata in order to quickly identify duplicate and similar files that are wasting disk space.
One of rmlint's standout features is its ability to find partial and fuzzy duplicates - files that have overlapping content but are not identical byte-for-byte. This allows it to identify wasted space even for files like documents, log files, backups, and more where some contents change over time while other parts stay the same.
Beyond just finding duplicates, rmlint offers a comprehensive set of options for analyzing duplicates and reclaiming wasted space. You can dig into the duplicate sets to see how they differ, preview deletions before committing them, and select exactly which files should be deleted or hard-linked together. It also integrates with compression utilities for gzipping duplicate files.
In summary, rmlint focuses specifically on the problem of wasted disk space from duplicate files. With flexible duplicate detection and review options, it helps you reclaim gigabytes or even terabytes of unnecessary duplicated data.
Rmlint Features
Features
Finds duplicate files
Identifies identical and similar files
Scans directories recursively
Builds database of file checksums
Quickly finds duplicates
Saves disk space by removing duplicates
Pricing
Open Source
Pros
Free and open source
Fast and efficient
Finds even partially duplicated files
Cross-platform
Customizable duplicate finding rules
Command line and GUI versions available
Cons
Can be resource intensive for very large filesystems
Cryptic command line interface
GUI version is basic
Requires some technical knowledge to use effectively
Duplicate Cleaner is a utility software designed to help users identify and remove duplicate files from their computers or storage devices. It works by scanning drives and building an internal database of your files' contents using sophisticated algorithms. It can then find files that have identical data, even if the...
dupeGuru is an easy-to-use utility program designed to help users find and manage duplicate files on their computers. It works on Windows, macOS, and Linux operating systems.With an intuitive interface, dupeGuru scans specific folders or entire drives to detect duplicate and similar files based on content analysis or file attributes....
Gemini 2 is a user-friendly duplicate file finder and cleaning utility designed specifically for Mac. It enables users to quickly find and remove duplicate files and folders from their hard drives and external drives connected to their Mac.When launched, Gemini 2 performs a deep scan of the user's chosen drives...
AllDup is a free and open-source duplicate file finder and remover for Windows. It can help detect duplicate files based on content, not just file names, allowing you to comprehensively find copies taking up unnecessary space.AllDup scans local drives and external storage devices, building an index of file contents using...
FSlint is an open-source command-line utility for finding and cleaning duplicate and obsolete files on Linux and Unix-like operating systems. It recursively scans specified directories to identify the following types of redundant files that waste disk space:Exact duplicate filesPartial duplicate files with overlapping contentRenamed duplicate filesEmpty files and directoriesOld backup...
Anti-Twin is an anti-plagiarism software used mainly in academic settings to detect plagiarism and duplicated text in student assignments. It works by comparing student submissions against an extensive database of web sources as well as previously submitted papers to identify any passages or sections that match another text too closely.Once...
Czkawka is an open-source duplicate file finder and disk analyzer software for Windows.It helps users find duplicate files, similar images, large files, empty folders and other unwanted data on their hard drives. The goal is to help clean up disks and regain wasted space.Key features of Czkawka:Finds exact duplicate files...
Ollie is an innovative AI-powered photo organizer app that helps you automatically tag, search and manage your growing photo library. It uses advanced computer vision and machine learning technology to scan all your photos and detect faces, places, objects and more to apply smart tags and group similar photos together.One...
Duplicate Directories and Files Finder is a utility software designed to help users identify and remove duplicate files and folders on their computers or storage drives. It provides an easy way to find redundant copies of files that are taking up unnecessary space.The software performs an in-depth scan of your...
Doublekiller is a free, open-source duplicate file finder and remover for Windows. It can help you identify duplicate copies of files on one or more drives and reclaim valuable disk space.Doublekiller scans your selected drives or folders using an MD5 hash comparison to efficiently find files that have identical content,...
CloneSpy is an open-source alternative to Red Gate's Reflector .NET decompiler and browser for .NET assemblies. It enables .NET developers to easily browse, decompile and analyze the source code of .NET assemblies without needing the original source code.Some key features of CloneSpy include:Supports decompiling assemblies targeting .NET Framework versions 1.0...
Auslogics Duplicate File Finder is a free Windows utility designed to help users identify and remove duplicate files from their computer system. It provides an easy way to find copied files that are either exactly identical or very similar, allowing the user to delete unnecessary duplicates and recover valuable hard...
Samesame is a free, open-source duplicate file finder software for Windows, Mac, and Linux. It can help you reclaim disk space by identifying redundant copies of files on your hard drives.Samesame scans your selected folders and drives to build an internal index of the files' contents. Using cryptographic hashing algorithms,...
WinExt Free is a free system enhancement utility for Windows that provides users with extra features and customization options to improve their experience. It serves as an all-in-one toolkit that enables tweaking, optimizing, personalizing and enhancing various aspects of the Windows operating system.Some of the key features of WinExt Free...
GDuplicateFinder is an open source duplicate file finder for Linux systems. It is designed to help users identify and remove duplicated files to save disk space.Key features of GDuplicateFinder:Scans local drives for duplicate files based on MD5 checksumsSupports ext2, ext3, ext4, ReiserFS, FAT32, and NTFS file systemsFilters duplicate files by...
Singlemizer is a free, open-source duplicate file finder and removal tool for Windows. It scans local and external drives to detect duplicate files taking up unnecessary space.Once scanning is complete, Singlemizer provides an intuitive interface to view and manage duplicate files. It groups identical files together and allows the user...
Decloner is an open-source duplicate code detection tool for software projects. It analyzes code bases to identify cloned or similar code blocks and generates reports highlighting duplicate fragments down to the line level.Decloner helps reduce code duplication which in turn improves maintainability. Removing copied/pasted code means there is less to...
i-DeClone is a powerful yet easy-to-use disk cloning and imaging software for Windows. It enables creating exact copies of hard drives, partitions or logical drives for various purposes like backup, migration to new hardware, deploying master images to multiple computers, etc.Some key features of i-DeClone include:Sector-level disk copies ensuring every...
Bytessence DuplicateFinder is a user-friendly duplicate file finder and removal software for Windows. It allows users to efficiently find and delete duplicate files taking up unnecessary space on their hard drives.DuplicateFinder thoroughly scans local drives, external storage devices, and specific folders specified by the user. It analyzes files based on...