BasicSR is an open-source neural speech recognition toolkit based on deep learning. It provides an end-to-end speech recognition pipeline to transcribe raw audio into text.
An open-source neural speech recognition toolkit providing an end-to-end speech recognition pipeline for transcribing raw audio into text.
What is BasicSR?
BasicSR is an open-source neural speech recognition toolkit for researchers and developers. It is built using deep learning techniques to provide an end-to-end speech recognition pipeline. BasicSR takes raw audio as input and outputs transcribed text.
Some key features of BasicSR:
Implemented with PyTorch and provides modular and customizable neural network components
Supports model training and inference for speech recognition
Includes pretrained models for English and Mandarin Chinese
Provides data preprocessing tools for feature extraction from audio
Optimized for GPU acceleration and can scale to multiple GPUs
Active open-source development community for contributions
BasicSR aims to advance speech recognition research by providing an open and flexible toolkit. The goal is to reduce time spent on implementation, so researchers can focus more on novel techniques and model architectures to push the state-of-the-art in speech recognition performance.
BasicSR Features
Features
End-to-end neural network based speech recognition pipeline
Supports training acoustic and language models from scratch
Modular design allows customization and extension
Open source with permissive license (MIT)
Pricing
Open Source
Pros
Free and open source
Active development community
Customizable and extensible
Good performance for basic models
Cons
Requires expertise in deep learning and speech recognition
Magnific AI is an artificial intelligence platform designed to help businesses leverage the power of AI to increase productivity, efficiency, and insights. It serves as a digital assistant that can understand requests in natural language and complete tasks automatically.Some of the key capabilities of Magnific AI include:Document summarization - It...
Upscayl is an AI-powered photo enhancement software that specializes in upscaling images. It utilizes cutting-edge machine learning and deep learning algorithms to increase the resolution of images while preserving or enhancing details.When you input a low-resolution image into Upscayl, its artificial intelligence examines the image and intelligently increases the number...
waifu2x is an open-source image scaling and noise reduction software aimed primarily at enlarging anime and manga style images. It utilizes deep convolutional neural networks to learn the finer details in low resolution images and then applies that learning to increase image sizes while preserving much of the original detail...
Magickimg is a powerful yet easy-to-use open source software suite for editing and manipulating images through the command line. It is based on ImageMagick, a well-established graphics library, and aims to simplify many common image processing tasks.Some key features and capabilities of Magickimg include:Resizing images while preserving aspect ratioCropping and...
AiToolsKit.ai is a versatile AI toolkit aimed at creative professionals like graphic designers, copywriters, web developers, and more. It brings together a suite of AI models and algorithms to help automate mundane tasks and boost creative workflows.Some of the key features of AiToolsKit.ai include:AI image generation - Generate unique images,...
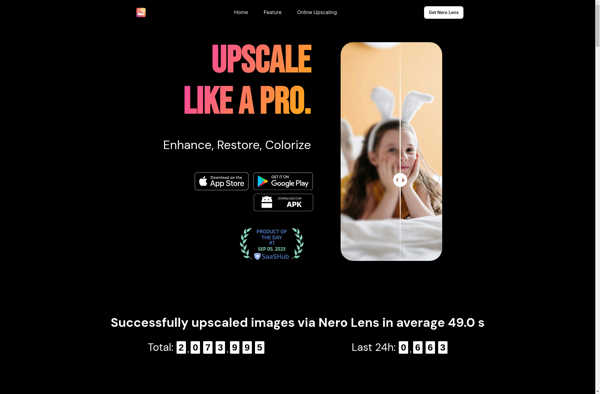
Nero Lens is an advanced image upscaling and enhancement software that utilizes the power of artificial intelligence to enlarge and improve the quality of low resolution images. It employs deep learning techniques to sharpen details, reduce artifacts, and reconstruct missing information in order to produce high-resolution versions of input images.The...
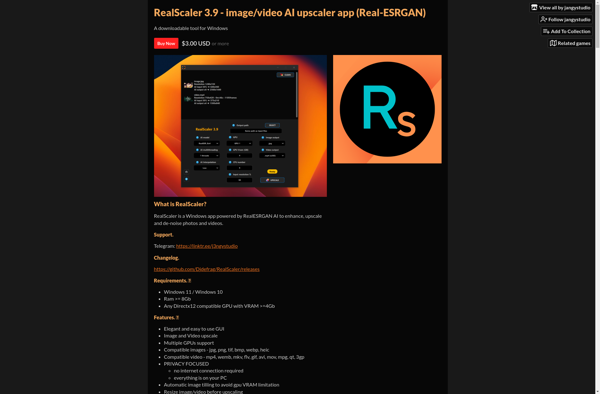
RealScaler is a scalable operations software designed to help businesses intelligently automate processes and make data-driven decisions. It utilizes artificial intelligence and machine learning to provide real-time analytics, identify optimization opportunities, predict outcomes, and streamline workflows.Key features of RealScaler include:Smart dashboard showing key metrics and trendsAutomated reporting and notificationsPredictive analytics...
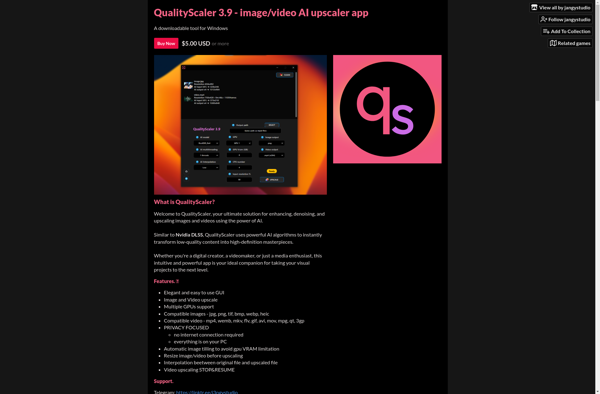
QualityScaler is an artificial intelligence-powered software application designed to analyze and enhance the quality and resolution of digital images and videos. The software utilizes advanced deep learning algorithms to upscale images and videos to higher resolutions and improve overall quality.Some key features of QualityScaler include:Upscaling images and videos up to...
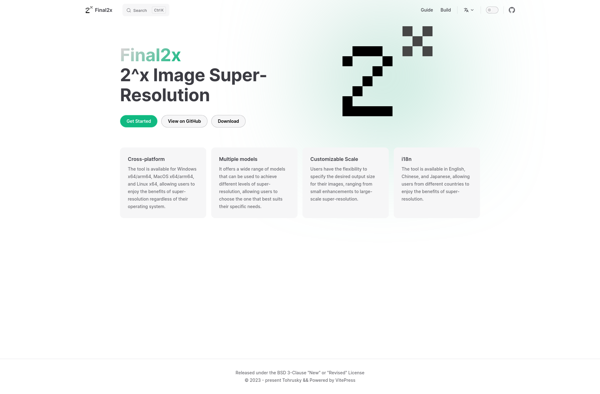
Final2x is an open source, cross-platform software that utilizes cutting-edge machine learning algorithms to upscale images and videos to higher resolutions with high fidelity. It supports upscaling images up to 4K resolution and videos up to 1080p.The software leverages deep learning models trained on millions of images to intelligently enlarge...