CMU Sphinx is an open source speech recognition toolkit developed at Carnegie Mellon University. It features acoustic model training, language model integration, and decoding for speech recognition applications.
CMU Sphinx: Open Source Speech Recognition Toolkit
Open source speech recognition toolkit developed at Carnegie Mellon University, featuring acoustic model training, language model integration, and decoding for speech recognition applications.
What is CMU Sphinx?
CMU Sphinx is an open source speech recognition toolkit originally developed at Carnegie Mellon University. It is used to add speech recognition capabilities to applications by providing the necessary components like acoustic model training, language model integration, and decoding.
Some key features of CMU Sphinx include:
Acoustic model training - Ability to train acoustic models from audio and text transcripts to improve recognition accuracy
Language model support - Integrate statistical or grammar-based language models to improve recognition of fluent speech
Decoders - Decode audio into text by matching against acoustic and language models
Cross-platform - Available on Linux, Windows, Mac, and other platforms
Customizable - Open source allows customization for specific use cases
Active community - Large open source community providing support and additional modules
CMU Sphinx is used in applications like voice user interfaces, transcriptions, dictation software, car systems, robotics, and more. With its modular architecture, it can be easily integrated or customized. The open source nature also allows companies to adapt it for commercial products.
Nuance Dragon is a advanced speech recognition software that allows users to dictate text and control their computer using only their voice. It provides capabilities like:Accurately transcribing audio recordings and live speech into text documents or formats like Microsoft Word.Controlling computer functions completely hands-free using speech commands, like opening files,...
Whisper is an AI-powered voice assistant mobile app launched in 2022 that allows users to have natural conversations with an AI assistant. It uses advanced language processing to understand questions, requests, and descriptions from users in order to provide helpful information, recommendations, and responses.Some key features of Whisper include:Conversational AI...
Windows Speech Recognition is a speech-to-text software application developed by Microsoft and included in Windows Vista and later Windows operating systems. It allows users to control their computer and enter text by speaking into a microphone.Some key features of Windows Speech Recognition include:The ability to dictate documents, spreadsheets, presentations, emails,...
Dictandu is a free online dictionary and translation service developed as an open source project. It provides users with quick access to definitions, translations, synonyms, pronunciations and other information for millions of words and phrases across over 100 languages.Some key features of Dictandu include:Intuitive search allowing users to look up...
Blather is an open-source, self-hosted microblogging software written in Ruby that allows users to post short text-based posts up to 200 characters. It has a similar functionality to Twitter, allowing users to follow updates from people they are interested in.Some key features of Blather include:Simple and clean interfaceSupport for hashtags,...
Dictanote is a free note taking and organization software for Windows. It provides a simple yet powerful way to create, organize, and find notes quickly.Some key features of Dictanote include:Create rich text notes with formatting, checklists, embeds, and imagesAdd tags and categories to notes for easy filtering and searchSearch notes...
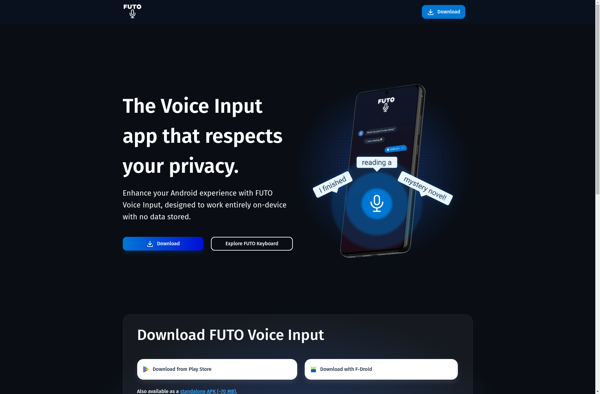
FUTO Voice Input is a powerful speech recognition software that allows users to control their computer and type using only their voice. It utilizes state-of-the-art speech recognition technology to accurately transcribe speech into text.Some key features of FUTO Voice Input include:Highly accurate speech recognition engine that can understand natural language...
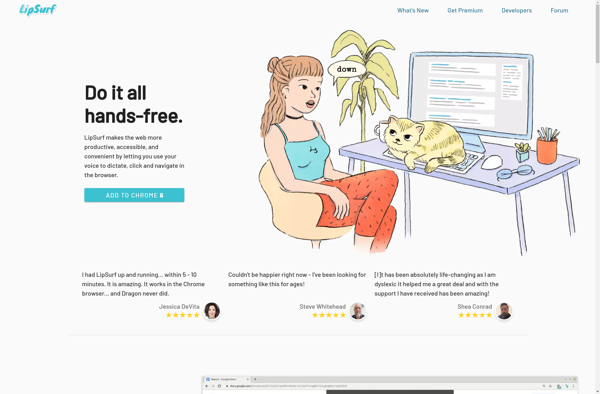
LipSurf is an open-source software application designed specifically for speech-language pathologists and researchers studying speech motor control. It provides tools for recording, analyzing, and visualizing articulatory movements during speech production using imaging modalities like ultrasound, MRI, or video.Key features of LipSurf include:Importing and synchronizing audio and articulatory imaging dataCorrecting and...
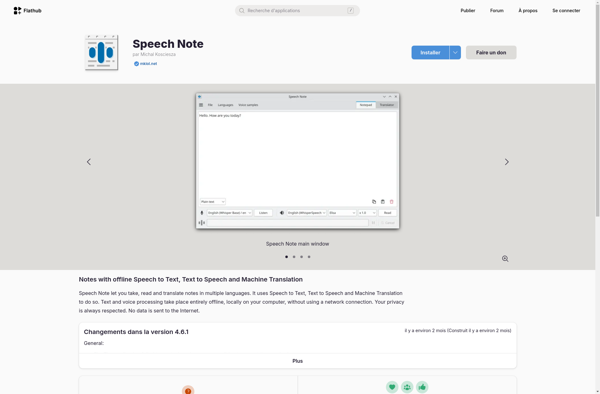
Speech Note is voice recognition software that utilizes advanced speech-to-text technology to convert spoken words into digital text quickly and accurately. It is an invaluable productivity tool for anyone who needs to generate written documents and notes without typing.With Speech Note, users can dictate naturally using their voice and see...
Nerd Dictation is a powerful voice recognition software that allows users to efficiently dictate text using only their voice. It utilizes advanced speech recognition technology to accurately transcribe speech into text in real-time. Some key features of Nerd Dictation include:Seamless dictation with built-in support for common punctuation marks, editing commands,...
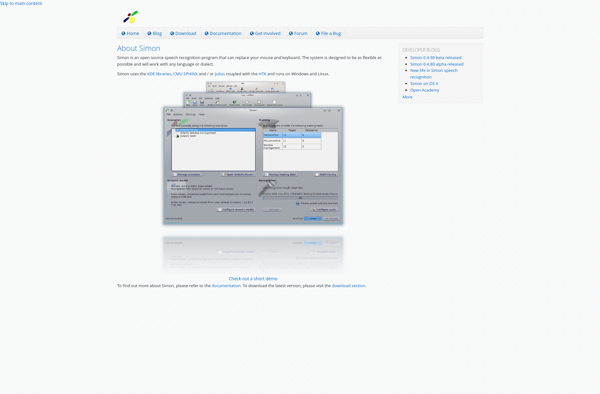
Simon Speech Recognition is an open-source, offline speech recognition application developed by Anthropic. It enables users to dictate text and issue voice commands on their computer without requiring an internet connection.Some key features of Simon Speech Recognition include:High accuracy speech-to-text transcriptionSupport for issuing voice commands to control your computerCompletely offline...
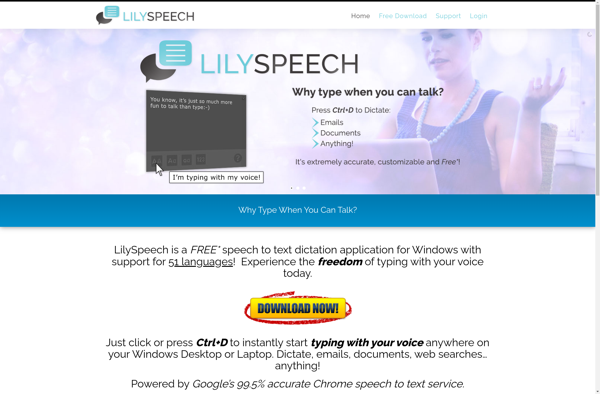
Lilyspeech is an innovative text-to-speech (TTS) software that utilizes advanced artificial intelligence to convert text into human-like speech. Developed by Anthropic, Lilyspeech features a state-of-the-art neural network architecture fine-tuned on massive datasets to generate high-quality and natural sounding voice recordings.Unlike traditional TTS systems that sound robotic and unnatural, Lilyspeech produces...
VoxCommando is a smart voice assistant software designed specifically for podcasters, video creators, videographers, and other media professionals. It utilizes advanced voice recognition and AI technologies to provide automated transcription, editing tools, and content search features.One of the main benefits of VoxCommando is its ability to automatically transcribe audio and...
Kaldi is an open-source toolkit for speech recognition research, released under the Apache License 2.0. It is written in C++ and is known for its flexibility, modularity, and active community support.Some key features and capabilities of Kaldi:Implements common speech recognition techniques like Gaussian mixture models, deep neural networks, feature extraction,...