Datura is an open-source, self-hosted web spider and web crawler written in Java. It allows collecting structured data from websites through crawling, scraping, parsing, and data extraction. Datura is designed for flexibility, scalability, and easy integration.
Discover the powerful open-source web spider and crawler, Datura, designed for flexibility, scalability, and easy integration, ideal for collecting structured data from websites through crawling, scraping, parsing, and data extraction.
What is Datura?
Datura is an open-source, self-hosted web spider and crawler written in Java that allows users to extract and gather structured data from websites. It can crawl multiple sites and pages based on configured seeds and sitemaps, scrape data, parse content, and extract information.
Some key features of Datura include:
Highly customizable crawling with support for breadth-first and depth-first approaches
Flexible content parsing and data extraction using XPath queries and regular expressions
Plugin architecture for adding custom processors and outputs
Scalable through distributed architecture and integration with big data frameworks like Hadoop and Spark
Easy to deploy, manage, and monitor through web UI and REST API
Available on GitHub and Maven Central repo for easy integration
Datura is designed to be flexible, scalable and easy to integrate with other applications. It can be used for structured data mining, content monitoring, SEO analysis, research, and other use cases involving large-scale web crawling and scraping. The open-source nature also allows custom enhancements and modifications.
Datura Features
Features
Web crawler
Web scraper
Data extraction
Flexible and customizable
Scalable
Self-hosted
Open source
Pricing
Open Source
Pros
Free and open source
Self-hosted allows control over data
Scalable for large datasets
Customizable for specific needs
Java-based for cross-platform use
Cons
Requires technical skills to set up and manage
No official support offered
Potential legal issues around scraping without permission
Adobe Media Encoder is a powerful and versatile video encoding and conversion application that is included as part of Adobe's Creative Cloud suite. It allows users to efficiently process video files for delivery to broadcast, web, devices, and other platforms.Media Encoder can batch encode video files into a wide range...
What Is Freemake Video Converter?Freemake Video Converter is a free video conversion tool for Windows that handles over 500 formats including MP4, AVI, MKV, WMV, MOV, FLV, and 3GP. It also rips DVDs, burns Blu-ray discs, and creates photo slideshows with music.Key FeaturesThe converter supports batch processing, hardware-accelerated encoding, subtitle...
Total Video Converter is a versatile video conversion and editing software for Windows. It supports converting between a wide range of video formats including AVI, MP4, WMV, MOV, MKV, FLV, 3GP, WebM and more. Some of the key features include:Ability to convert single video files as well as batch convert...
MEncoder is a versatile command-line video transcoding tool that is part of the larger MPlayer project. It can decode and encode between various video and audio formats, giving advanced control over parameters like bitrate, frame rate, resolution, codecs, and more.Some key features of MEncoder include:Supports a wide variety of multimedia...
TEncoder Video Converter is a free, open-source video transcoding software for Windows. It allows users to easily convert between a wide range of video file formats including MP4, AVI, MKV, WMV, MOV, FLV and more. Some key features include:Intuitive and easy-to-use interface for beginnersSupports converting video files in batchOffers basic...
MainConcept TotalCode Studio is a comprehensive video codec software suite for encoding, decoding, and transcoding media files and streams. It supports a wide range of formats including HEVC/H.265, AVC/H.264, MPEG-2, AV1 and popular container formats like MP4, MKV, and MPEG-TS.As a professional encoding solution, TotalCode Studio offers advanced compression options...
ffWorks is a free and open-source office suite for Windows that includes many of the same applications found in paid options like Microsoft Office. It includes full-featured software to handle word processing, spreadsheets, presentations, and more.The word processor has similar functionality to Word, allowing you to format documents and insert...
Prism Video Converter is a versatile and easy-to-use video conversion application for Windows. It supports a wide range of video and audio file formats making it easy to convert videos for playback on various devices and platforms.Some of the key features of Prism Video Converter include:Converts between formats such as...
ffmpegX is a free and open-source graphical user interface application for macOS that wraps the features and encoding options of the popular ffmpeg command line tool into an easy-to-use interface.With ffmpegX, anyone can convert audio and video files between various formats, extract audio from video files, clip and cut video...
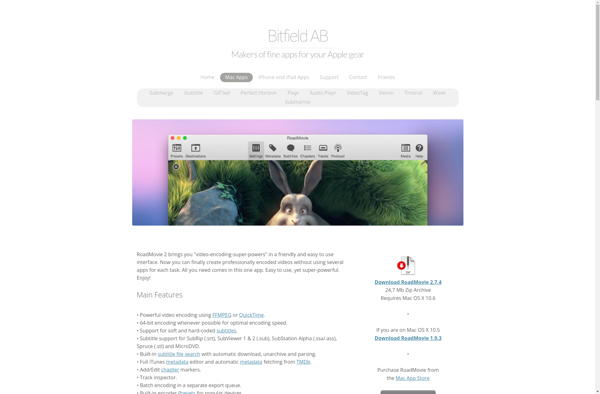
Roadmovie is an open-source, cross-platform video editing application aimed at beginners. It provides a simple but capable feature set for basic video editing needs.Some of the key features of Roadmovie include:Trimming, splitting and joining video clipsAdding transitions between video clipsOverlaying titles and creditsImporting and editing audio tracksApplying visual effects like...
ACDSee Video Converter is video conversion software developed by ACD Systems for Windows and macOS. It allows users to convert video files between a wide range of formats including AVI, WMV, MOV, MP4, MKV, FLV, 3GP, MPEG-1, MPEG-2, and more.Some key features of ACDSee Video Converter include:Intuitive and easy-to-use interface...
ffmpeg2theora is a free and open-source command-line tool for converting digital video into the open Ogg Theora video compression format. It is used to provide an open alternative to proprietary video codecs like H.264.ffmpeg2theora utilizes the popular ffmpeg multimedia framework for decoding various input video container formats like AVI, MKV,...