Heritrix is an open-source, extensible, web-scale, archival-quality web crawler project built on the Apache stack. It is designed for archiving periodic captures of content from the web and large intranets.
An open-source, extensible web crawler project built on Apache stack for archiving periodic captures of content from the web and large intranets.
What is Heritrix?
Heritrix is an open-source web crawler software project that was originally developed by the Internet Archive. It is designed to systematically browse and archive web pages by recursively following hyperlinks and storing the content in the WARC file format.
Some key features of Heritrix include:
Extensible and modular architecture based on Apache standards to support customization
Respects robots.txt and other directives to avoid overloading servers
Supports metadata extraction, post-processing of archived data, recovery from errors
Distributed architecture for high performance, scalability and robustness
Advanced configuration for in-depth crawling jobs targeting specific parts of websites
Heritrix is well-suited for building specialty search engine indexes, archiving online content for preservation purposes, and offline browsing of websites. Its focused crawling features allow users to customize crawl scopes and avoid unrelated content.
While Heritrix excels at archival-quality crawls, it has higher overhead than some other crawler software. It prioritizes quality, completeness and politeness over crawling speed. Heritrix is typically run on powerful servers and can handle complex, large-scale web crawling projects.
Heritrix Features
Features
Crawls websites to archive web pages
Extensible and customizable architecture
Respects robots.txt and other exclusion rules
Handles large-scale web crawling
Supports distributed crawling across multiple machines
Recovers from crashes and network problems
Provides APIs and web interface for managing crawls
What Is Algolia?Algolia is a hosted search API that provides fast, relevant search experiences for websites and applications. It powers the search functionality for thousands of sites including Stripe, Twitch, Medium, and Slack, delivering results in under 50 milliseconds.Key FeaturesAlgolia provides typo-tolerant full-text search, faceted filtering, geo-search, and AI-powered relevance...
Expertrec Search Engine is an innovative search technology that aims to revolutionize the way people find information online. Unlike traditional keyword-based search engines, Expertrec utilizes advanced artificial intelligence and natural language processing to understand the intent behind search queries.When a user enters a question or phrase into the Expertrec search...
WordPress i-Search Pro is a premium search engine plugin for WordPress that allows site owners to add advanced search functionality to their websites. It is designed specifically for WordPress and seamlessly integrates with any WordPress theme and site structure.The key features of WordPress i-Search Pro include:Fast indexing and searching -...
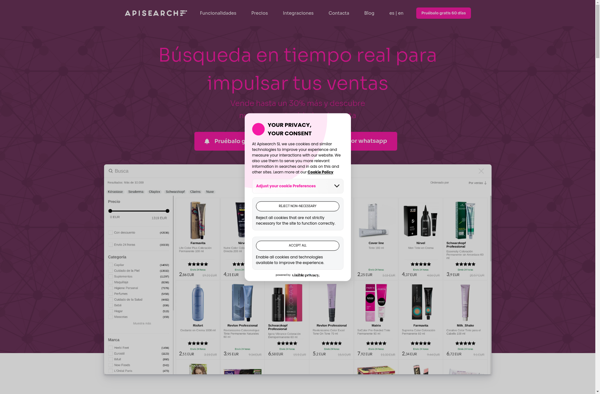
Apisearch is an open-source search platform developed by Apisearch Technologies. It provides a REST API to add advanced search functionality to applications and websites.Some key features and benefits of Apisearch include:Easy to integrate - Apisearch has clients for many programming languages and frameworks that make integration simple.Blazing fast - Indexing...
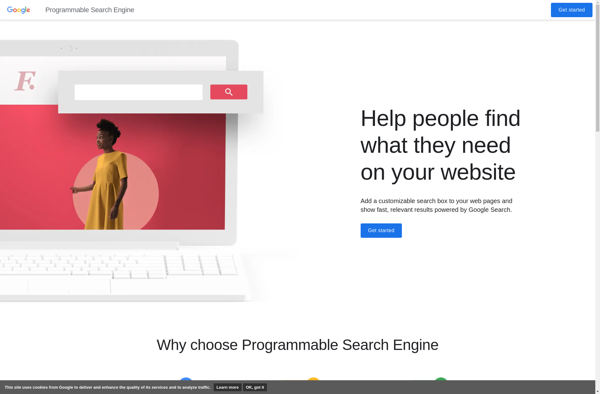
Google Custom Search Engine is a free service from Google that allows you to create a custom search engine for your website, blog, or a group of websites. It gives you more control over the search experience compared to the traditional Google web search.Some key features of Google Custom Search...
Apache Nutch is an open source web crawler software project written in Java. It provides a highly extensible, fully featured web crawler engine for building search indexes and archiving web content.Nutch can crawl websites by following links and indexing page content and metadata. It supports flexible customization and pluggable parsing,...
Mixnode is a privacy-focused web browser developed by Mixnode Technologies Inc. Its main goal is to prevent user tracking and protect personal data when browsing the internet.Some key features of Mixnode include:Blocks online ads and trackers by default to limit data collectionOffers encrypted proxy connections to hide user IP addresses...
StormCrawler is an open source distributed web crawler that is designed to crawl very large websites quickly by scaling horizontally. It is built on top of Apache Storm, a distributed real-time computation system, which allows StormCrawler to be highly scalable and fault-tolerant.Some key features of StormCrawler include:Horizontal scaling - By...
ACHE Crawler is an open-source web crawler written in Java. It provides a framework for building customized crawlers to systematically browse websites and collect useful information from them.Some key features of ACHE Crawler include:Scalable architecture based on distributed computing to crawl large sites quicklyFlexible plugin system to add customized data...