Grabtxt
Grabtxt: Free Web Scraping Tool
Extract text, links, images, documents, and data from any webpage with Grabtxt, a simple and intuitive web scraping tool, no coding required.
What is Grabtxt?
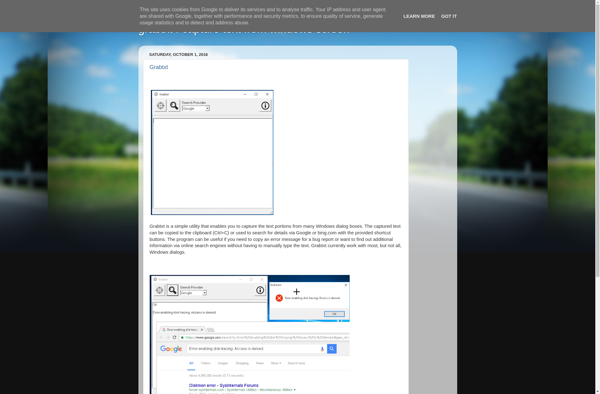
Grabtxt is a free and easy-to-use web scraping tool for extracting text, links, images, documents, and data from webpages without needing to write any code. It has an intuitive graphical interface that allows anyone to visually select elements on a webpage and extract their content.
To use Grabtxt, you simply enter the URL of the page you want to scrape, then click on the elements you want to extract. For example, if you want to scrape all the text from an article, you would click on the paragraph tags. If you want to scrape a table of data, you would click on the table itself. As you select elements, Grabtxt automatically generates the scraper code behind the scenes.
Once you have built your scraper, you can run it with one click to extract the content you selected. Results can be copied directly or exported in a variety of formats like PDF, CSV, JSON, Excel and more for further analysis and usage in other applications. The scrapers can also be saved and scheduled to run automatically at specific time intervals.
Grabtxt requires no coding knowledge or experience to operate. Its visual interface and automation features make it easy for anyone to scrape data from the web. It works on most modern websites and can bypass many anti-scraping measures for reliable results. Grabtxt is free for personal and commercial use without any usage limits, making it a popular choice for individuals, developers, and businesses who want an easy web scraping solution.
Grabtxt Features
Features
- Extract text, links, images, documents and data from webpages
- Intuitive drag and drop interface for creating scrapers without coding
- Support for scraping dynamic websites
- Ability to scrape multiple pages and sites
- Export scraped data to CSV/Excel
- Browser extension for scraping pages directly
- Web scraper automation
- Cloud-based web scraping
- Visual web scraper editor
Pricing
- Free
Pros
Cons
Official Links
Reviews & Ratings
Login to ReviewThe Best Grabtxt Alternatives
View all Grabtxt alternatives with detailed comparison →
Top Ai Tools & Services and Web Scraping and other similar apps like Grabtxt
Here are some alternatives to Grabtxt:
Suggest an alternative ❐Capture2text
HyperSnap

NormCap
CaptureText

Easy Screen OCR
Capture Assistant
