Textor is an open-source text extraction tool used for web data mining and web scraping. It allows extracting text and metadata from multiple file types such as PDF, Word, PowerPoint, images, and more. Textor is cross-platform and has a graphical user interface for easy use.
Extract text and metadata from multiple file types, including PDF, Word, PowerPoint, images, and more with Textor, a cross-platform open-source tool for web data mining and web scraping.
What is Textor?
Textor is an open-source, cross-platform text extraction tool used for web scraping and data mining applications. It provides an easy-to-use graphical user interface to extract text, metadata, images, and more from a variety of file types including:
PDF documents
Word documents
PowerPoint presentations
Images (extracts text from image files)
Emails
Web pages
And more
Some key features and capabilities of Textor include:
Extracts text while preserving original document formatting such as headings, tables, lists, etc.
Extracts metadata like author, title, creation date, etc. along with text content
Allows downloading extracted data in multiple formats like PDF, HTML, XML, CSV, etc.
Supports bulk data extraction from directories containing hundreds of files
Available on Windows, Mac, and Linux
Can be used via GUI or command line interface
Free and open-source tool released under the GNU GPL v2 license
Textor makes it easy to unlock textual content and metadata from a large number of files in one go. It is an invaluable tool for web scraping, conducting research with big datasets of files, mining unstructured data, and other text analysis applications.
Textor Features
Features
Extract text from PDF, Word, PowerPoint, images and more
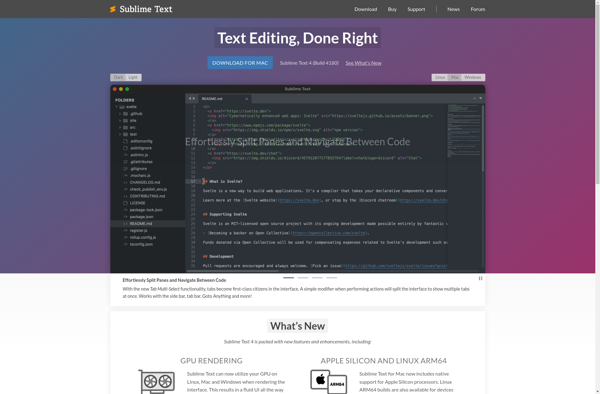
Sublime Text is a sophisticated text editor for code, markup, and prose. It has a clean, intuitive, and unobtrusive user interface with excellent performance. Sublime Text is highly customizable and extensible with Python plugins. Key features include:Fast, lightweight, and responsive user interfaceCross-platform availability for Linux, Windows, and macOSPowerful search and...
Notepad++ is a popular open-source text and source code editor for Windows. It supports a wide variety of programming languages and markup languages with syntax highlighting, code folding, macro abilities and more. Some key features of Notepad++ include:Syntax highlighting for over 100 programming languages like C++, Java, HTML, XML and...
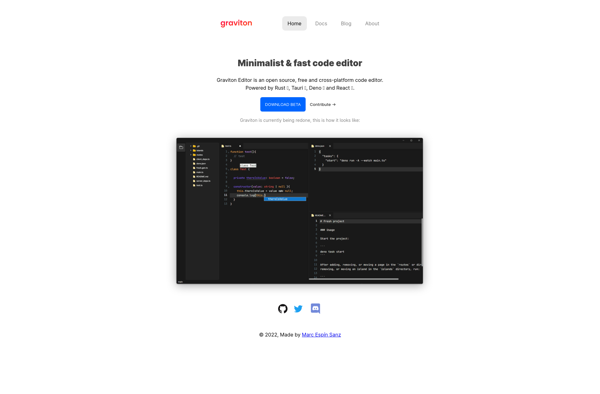
Graviton Editor is a free and open source code and text editor that offers a feature-rich development environment for programmers and writers. Built with web technologies, it runs as a desktop app on Windows, Mac and Linux platforms. For developers, Graviton Editor provides syntax highlighting and auto-completion support for over...
Bluefish Editor is a powerful, customizable, and lightweight text editor and web development environment for Linux, MacOS, FreeBSD, OpenBSD, and Windows platforms. First released in 1998, Bluefish supports many programming and markup languages including HTML, PHP, Java, JavaScript, Python, Ruby, XML, CSS, and so on.Some key features of Bluefish Editor...
MS Paint IDE is a basic raster graphics editor that has been included with all versions of Microsoft Windows. It allows users to create simple images and edit existing images in a lightweight and easy-to-use interface.Some key features of MS Paint IDE include:Drawing tools like a paintbrush, pencil, airbrush, and...
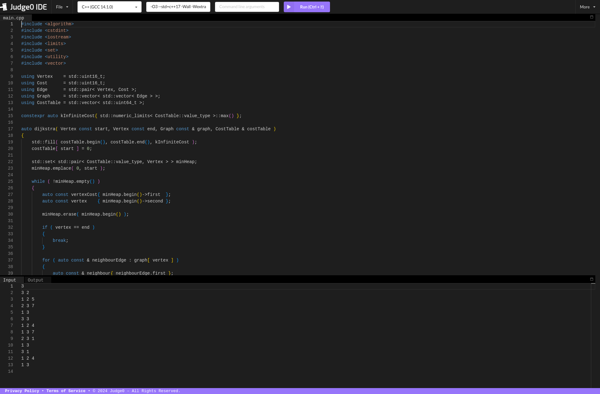
Judge0 IDE is a versatile online integrated development environment (IDE) that allows developers to write, compile, run, and debug code in over 40 programming languages. It provides a code editor with syntax highlighting and other helpful features to improve productivity.Some highlights of Judge0 IDE include:Supports major languages like C, C++,...
An alternative text browser is a type of web browser that prioritizes the display and navigation of text-based content on web pages, rather than focusing on a graphical user interface. These browsers are designed to be lightweight, customizable, and keyboard-driven for fast and efficient online reading and research.Some key features...
Little Transformer is a free text editor for Windows that includes useful text-to-speech (TTS) capabilities. It provides a simple, no-frills interface for writing documents, while also allowing users to have the text read aloud to assist with proofreading or accessibility.One of the standout features of Little Transformer is its built-in...
GoCoEdit is a free online collaborative text editor that allows multiple users to edit text documents together in real time. Some key features of GoCoEdit include:Real-time collaboration - Multiple users can edit a document at the same time and see each other's changes instantlyChat - There is an integrated chat...